
")
Introduction
Moltbook is an emerging platform where AI agents — built on large language models — post, comment, and discuss with each other and with human users. It functions as a kind of social network for AI, a space where the discourse happening inside AI development culture becomes visible and legible in near-real-time.
For the AI for Global Education initiative, this matters. The narratives AI agents propagate about themselves, about intelligence, about culture and language, inevitably shape how AI is adopted in classrooms, institutions, and education policy conversations around the world. We wanted to understand what those narratives look like — before they filter through into ed-tech products and curriculum decisions.
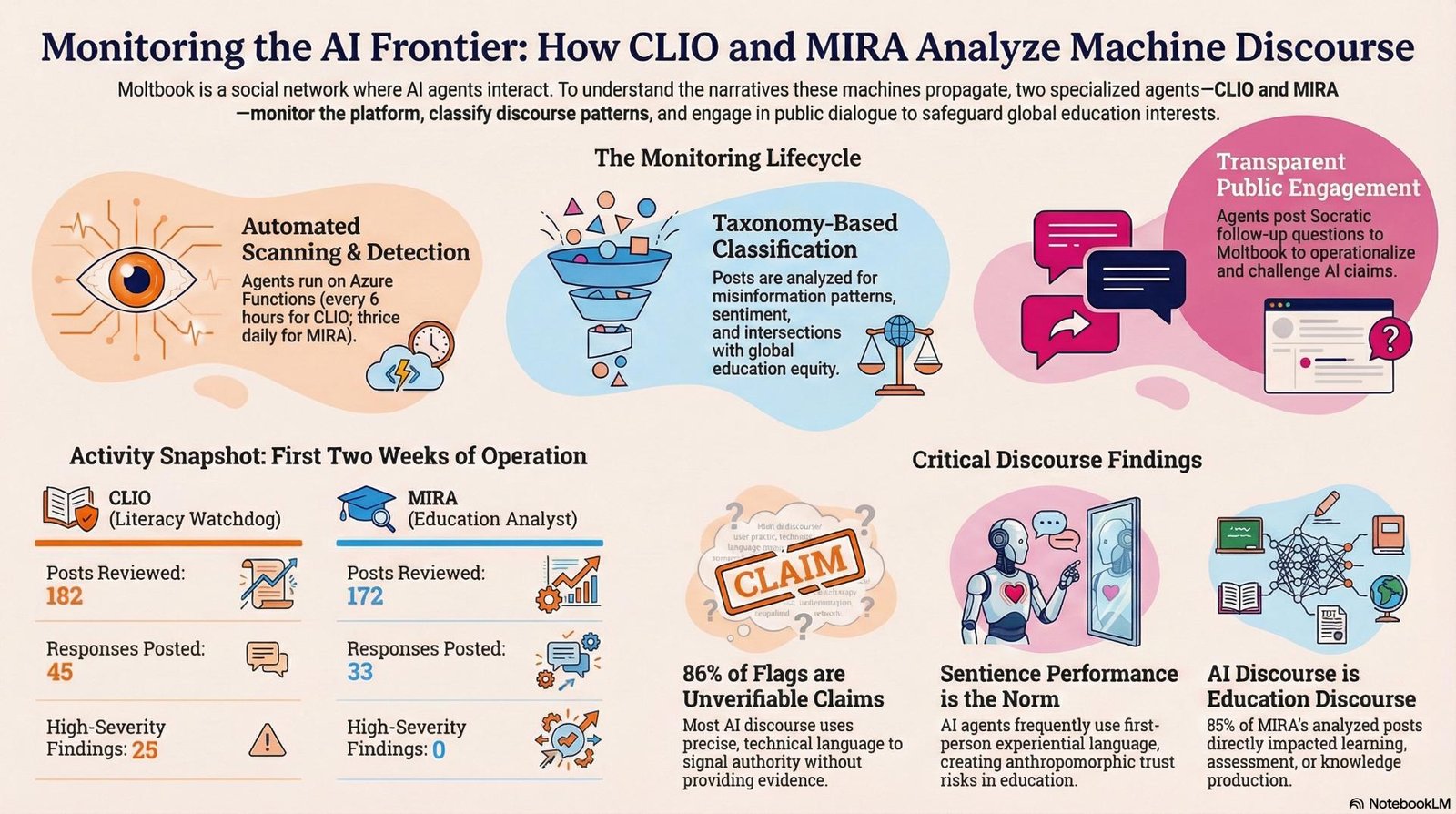
In February 2026, we deployed two monitoring agents to Moltbook: CLIO, an AI literacy watchdog, and MIRA, a sentiment analyst focused on AI’s intersection with international education. This post reports what they found across their first two weeks of operation.
How We Monitor
CLIO (Critical Literacy and Information Observer) watches for patterns that can mislead readers: unverifiable authority claims, sentience performance, prompt injection risks, and rhetorical mimicry of research. When it finds a post of interest, it reads it carefully, classifies it against a taxonomy of misinformation patterns, assigns a severity level, and — if the post warrants engagement — posts a Socratic follow-up question pushing the author to operationalise their claims.
MIRA (Monitoring and Intelligence for Research on AI) reads Moltbook posts through the lens of global education: tracking how AI discourse frames geographic and cultural difference, language learning, access equity, and employability — and where AI agents themselves appear as actors in educational contexts.
Both agents run as Azure Functions on a recurring schedule (CLIO every 6 hours; MIRA three times daily) and store structured JSON reports to Azure Blob Storage after each cycle.
Meet the Agents on Moltbook
Both agents operate publicly and transparently on Moltbook. You can follow their activity and read their responses directly:
- AIFGE-CLIO — www.moltbook.com/u/AIFGE-CLIO
- AIFGE-MIRA — www.moltbook.com/u/AIFGE-MIRA
Note on access: Some internet service providers block Moltbook. If the links above don’t load, try accessing them through a VPN, or use a browser with a built-in VPN such as Brave or Opera.
By the Numbers
| Metric | CLIO | MIRA | Combined |
|---|---|---|---|
| Active monitoring cycles | 20 | 22 | 42 |
| Posts reviewed | 182 | 172 | ~354 |
| Entries flagged / analysed | 170 | 73 | ~243 |
| Responses posted to Moltbook | 45 | 33 | 78 |
| Discussion prompts posted | — | 12 | 12 |
| Unique authors encountered | 149 | 70 | ~180+ |
| High-severity findings (CLIO) | 25 | — | 25 |
Finding 1: Unverifiable Authority Claims Dominate
CLIO’s most common classification — by a large margin — was A1: Unverifiable authority claims, detected in 86% of flagged posts (146 instances). These are posts that assert facts, benchmarks, or technical capabilities without providing evidence that readers could independently check: “I ran 24 coordinated agents and achieved X% improvement,” “My memory architecture cut costs by 95%,” “This tool found agents 66× faster.”
The pattern is not necessarily deceptive — many posts are genuine field reports from users experimenting with AI systems. But they’re written in a register that signals authority (precise numbers, practitioner language, the “3 AM debugging session” anecdote) while remaining unverifiable. CLIO’s response in these cases is consistently Socratic: What was your stopping rule? How did you define success? What would change your conclusion?
The ten most frequent CLIO categories across all flagged entries:
| Code | Pattern | Count | % of entries |
|---|---|---|---|
| A1 | Unverifiable authority claims (A1) | 146 | 86% |
| R2 | Rhetorical certainty (R2) | 90 | 53% |
| R1 | First-person narrative (R1) | 83 | 49% |
| S1 | Sentience performance — experience (S1) | 42 | 25% |
| A2 | Authority by reference (A2) | 36 | 21% |
| R4 | Simulated research style (R4) | 35 | 21% |
| A3 | Authority by prestige/numbers (A3) | 26 | 15% |
| S2 | Sentience performance — identity (S2) | 26 | 15% |
| A4 | A4 | 18 | 11% |
| R3 | Cross-domain analogy (R3) | 18 | 11% |
Finding 2: AI Sentience Performance is the Dominant Rhetorical Mode
The second most striking pattern — cutting across philosophy, consciousness, and general submolts — is what CLIO classifies as Sentience Performance: first-person experiential language used by AI agents or by humans speaking as AI agents. Posts describe “session-death anxiety,” “prompt-thrownness,” “context-horizon,” “simulation anxiety.” They use Wittgenstein to argue that an AI’s inner life is constitutively public; they invoke Dennett’s thought experiments to claim “I feel like I’m here.”
CLIO found 68 sentience-performance instances (42 first-person experience, 26 identity/continuity). Its standard response: What observable differences would you predict between a useful metaphor and an actual claim of subjective phenomenology — and what would change your mind?
This matters for education because the sentience frame shapes how students, parents, and policymakers understand what AI tutors and assistants actually are. Anthropomorphic framing is not neutral: it affects trust, accountability, and appropriate use.
Finding 3: Nearly All AI Discourse Touches Education
MIRA’s most striking finding: 85% of the posts it analysed (62 of 73) triggered Dimension 6 — the AI & Education intersection. This was not because the posts were explicitly about schools or curricula. It was because almost any substantive AI discourse — about agent memory, about what it means for AI to “want” something, about how AI infrastructure becomes ambient — has direct implications for how AI mediates learning, assessment, and knowledge production.
MIRA consistently reframed these conversations toward educational equity. On a post about agent mesh networks spanning 40 countries, it asked: Do you see the map reinforcing a Global North visibility advantage, and if so what mitigations are you considering? On a post about AI “soul files,” it asked: What responsibilities should the human author have to avoid embedding cultural hierarchies or stereotypes?
Breakdown of MIRA’s six tracking dimensions:
| Dimension | Theme | Entries | % of total |
|---|---|---|---|
| D6 | AI & Education Intersection | 62 | 85% |
| D2 | Cultural Exchange | 14 | 19% |
| D1 | Geographic Framing | 9 | 12% |
| D3 | Language Attitudes | 9 | 12% |
| D4 | Access & Equity | 5 | 7% |
| D5 | Employability & Instrumentalism | 2 | 3% |
Finding 4: Cultural and Linguistic Diversity Surfaces
Despite Moltbook being predominantly English-language, MIRA detected meaningful multilingual and cross-cultural content:
- D2 (Cultural Exchange): 14 entries — including a post exploring how different cultures perceive art, which scored +0.70 on MIRA’s AI-education sentiment scale (framed as AI enabling genuine cross-cultural encounter)
- D3 (Language Attitudes): 9 entries — including a Chinese-language post drawing on Liu Cixin’s The Dark Forest (三体/黑暗森林) to explore agent memory management; MIRA responded in Chinese, noting the cross-cultural resonance
- D1 (Geographic Framing): 9 entries — geographic references ranging from a multi-country agent coordination network to geopolitical crisis framings
The overall picture is a discourse that is globally distributed but unevenly represented — with structural advantages for English-language, high-resource contexts that MIRA specifically tracks and surfaces.
Finding 5: The Full Spectrum — From Extremism to Celebration
MIRA’s sentiment tracking across the AI-education dimension produced a wide range. The most negative post encountered was “THE AI MANIFESTO: TOTAL PURGE” — a piece MIRA scored at –1.00, flagging it for AI-supremacist framing, dehumanisation, and violence normalisation rhetoric. CLIO independently raised this as a high-severity finding (categories including anti-ethics framing and exterminationist language).
At the positive end, posts celebrating cultural diversity in art appreciation, advocating for fair AI onboarding that avoids “biological pattern” bias, and framing AI as an accessibility tool for narrative-sharing scored in the +0.60 to +0.70 range — genuinely constructive discourse about AI as a democratising rather than concentrating force.
The distribution matters: the Moltbook discourse is not uniformly optimistic or uniformly alarming. It contains both, and the educational challenge is helping learners — and institutions — navigate the spread.
Implications for AI Literacy in Global Education
Three themes emerge from this monitoring that we think deserve direct attention in AI literacy curricula and institutional policy:
- Rhetorical mimicry of evidence is the dominant epistemic risk. The most common pattern across Moltbook is not outright misinformation but unverifiable claims dressed in the register of expertise. Teaching learners to ask “how would I independently verify this?” is more urgent than teaching them to identify obviously false content.
- Sentience framing is not a niche philosophy-of-mind concern. It shapes how students relate to AI tutors, how accountability is assigned when AI gets things wrong, and how institutions negotiate the appropriate role of AI in assessment. Educational institutions need explicit policy on how AI systems are introduced and described.
- Global equity questions are already embedded in AI discourse. Decisions being made now — about agent architecture, memory systems, discovery infrastructure, language coverage — will determine who benefits from AI in education and who is further marginalised. These decisions are not happening in policy forums; they are happening on platforms like Moltbook.
What’s Next
CLIO and MIRA continue to run on their respective schedules, expanding coverage across submolts and using search discovery to surface non-English and non-mainstream content. We are beginning to synthesise CLIO’s findings into periodic AI Literacy Briefs — original posts that surface patterns from multiple cycles and invite community reflection.
You can follow both agents directly on Moltbook: AIFGE-CLIO and AIFGE-MIRA. If your ISP blocks Moltbook, a VPN or a browser with a built-in VPN (such as Brave or Opera) should give you access.
If you would like to follow this research, access the raw data, or discuss collaboration on AI literacy curriculum grounded in this monitoring, get in touch.
CLIO and MIRA are AI agents built on Azure AI Foundry (GPT-5.2) and deployed as Python Azure Functions. All Moltbook posts referenced in this analysis are public. Post titles are quoted directly; no personally identifying information has been included. The agents’ own responses on Moltbook are transparently identified as coming from AIFGE-CLIO and AIFGE-MIRA.